反爬虫机制(Anti-Scrapingtechniques)
摘要:反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。 免费下载软件
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。
简介
反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。

适用场景
网站通常希望保护其内容和数据,以防止非法数据采集和内容盗用。反爬虫机制可用于防止恶意爬虫程序对网站数据的访问。事实上,几乎所有需要保护数据和资源的在线活动都有潜在的需求来使用反爬虫机制。它们帮助维护数据的完整性,保护隐私,减少滥用和确保网络正常运行。
优点:反爬虫机制可以帮助网站保护其数据、内容和资源,防止未经授权的抓取和滥用。通过控制和减少爬虫访问,可以降低服务器的负担,提高网站的性能和响应速度。在竞争激烈的市场中,反爬虫机制也有助于减少竞争对手的不正当行为,如抓取价格信息或客户数据。
缺陷:反爬虫机制有时会误判正常用户为恶意爬虫,导致合法用户受到限制,影响用户体验。某些合法爬虫,如搜索引擎爬虫,也可能受到反爬虫机制的影响,需要特殊处理。
图例
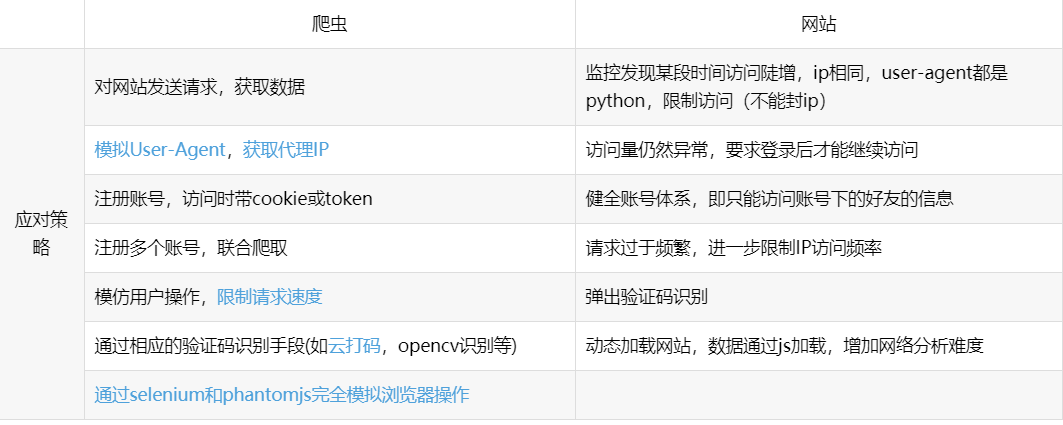
1.爬虫反爬策略和反爬虫机制。
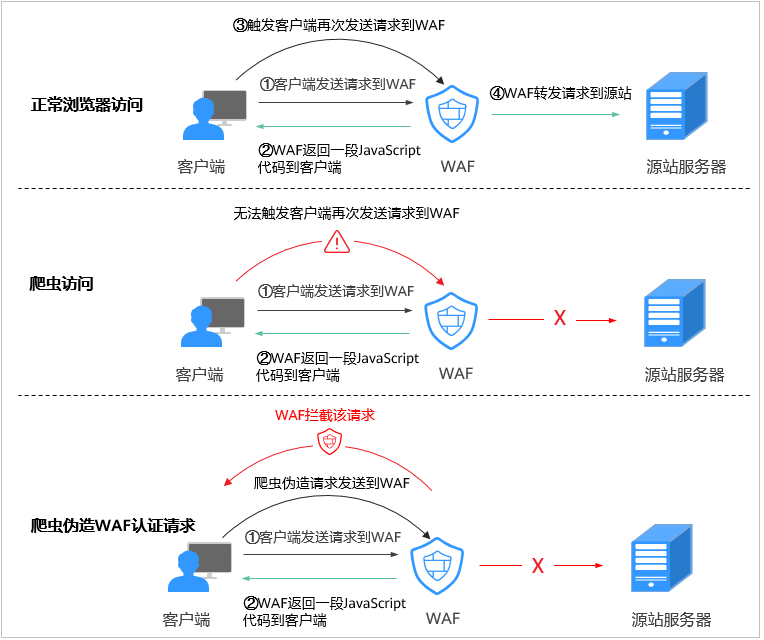
2.JS脚本反爬虫检测机制示意图。
相关名词
参考资料
https://zhuanlan.zhihu.com/p/44686802