网页抓取(Webscraping)
摘要:网页抓取是指从互联网上获取信息或数据的过程,通常通过自动化的程序来执行。这些程序被称为网络爬虫或网络机器人,它们浏览网页、提取信息并将其存储或进一步处理。 免费下载软件
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。
简介
网页抓取是指从互联网上获取信息或数据的过程,通常通过自动化的程序来执行。这些程序被称为网络爬虫或网络机器人,它们浏览网页、提取信息并将其存储或进一步处理。

适用场景
网页抓取是一种用于从互联网上获取信息的技术,广泛应用于数据挖掘、竞争情报、内容聚合、价格比较、搜索引擎优化、社交媒体分析、舆情监测、知识图谱构建以及自动化任务等领域。通过自动化地从网页上提取、分析和存储信息,网页抓取有助于用户获取所需的数据,以支持各种决策和创新。
优点:网页抓取的优点在于高度自动化,能实时更新数据,处理大规模信息,定制性强,适用于各种数据源,从网页数据到API和社交媒体等。这提高了数据获取的效率和灵活性,特别适用于需要实时追踪数据变化的应用,减少手动操作的负担。
缺陷:网页抓取的缺陷在于数据质量不稳定、可能引发法律和道德问题、应对网站反爬虫技术需要复杂性的编程、需要定期维护以适应网站变化、涉及敏感数据和隐私问题。
图例
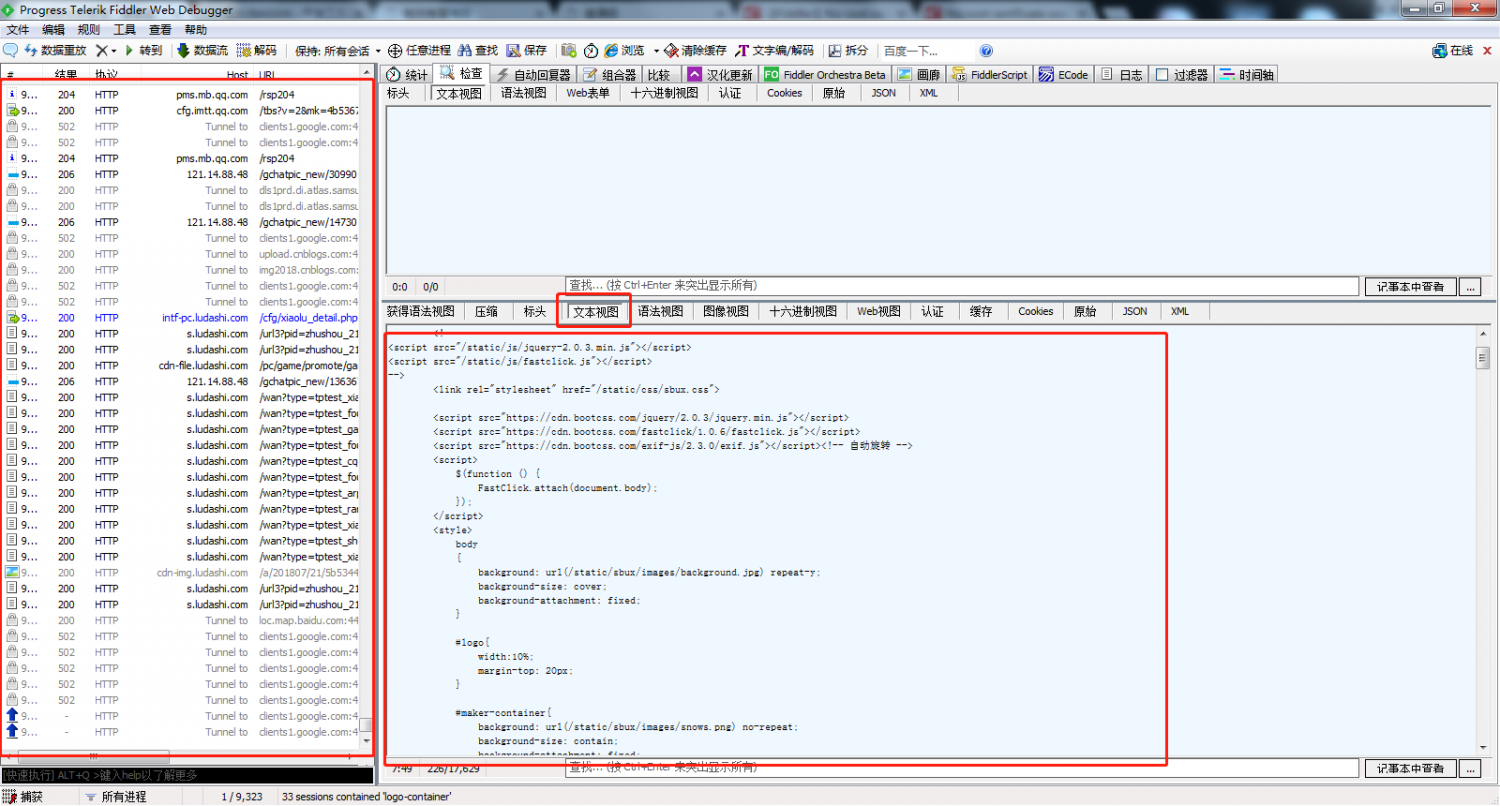
1. 网页抓取示例。
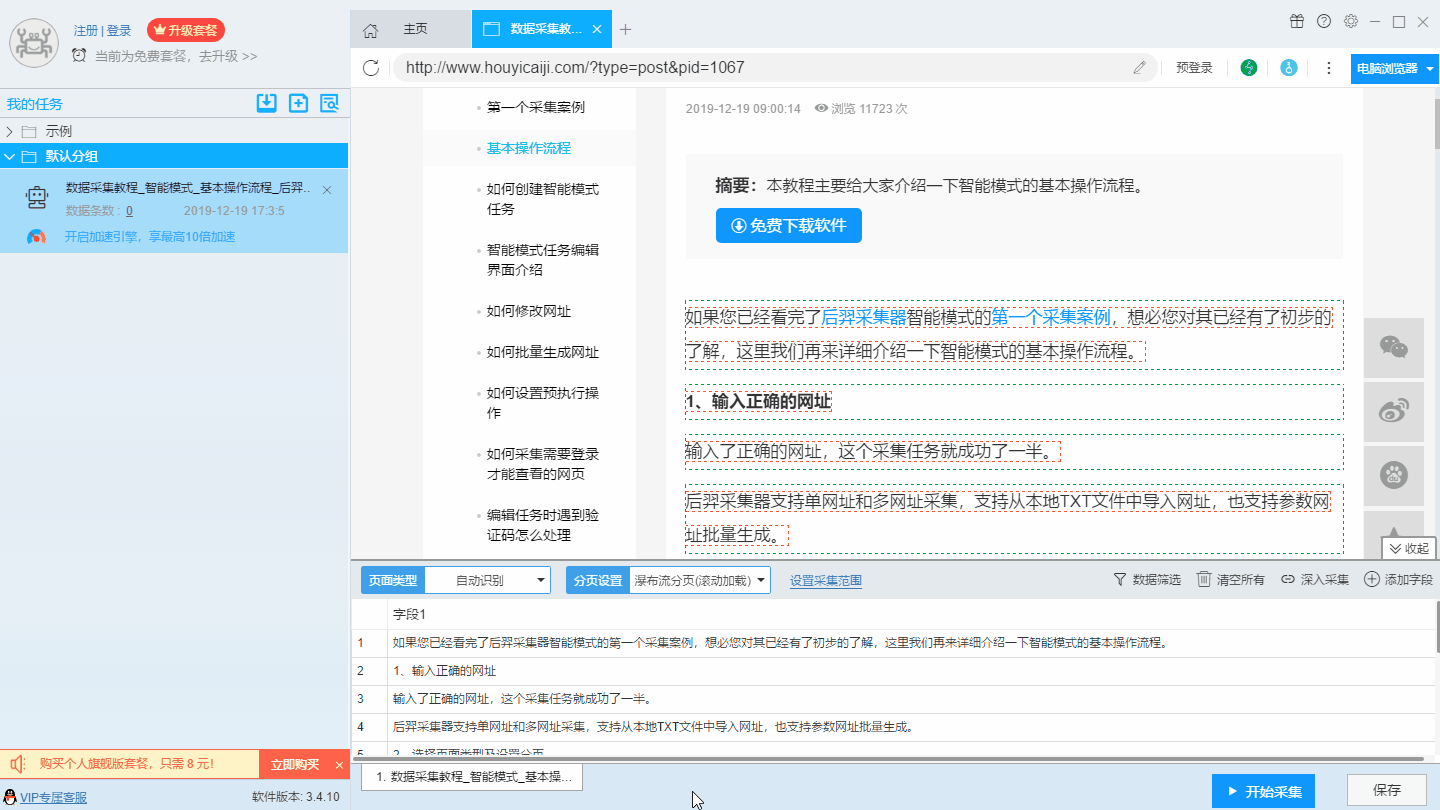
2. 后羿采集器网页抓取功能示例。
相关名词
参考资料
https://baike.baidu.com/item/%E7%BD%91%E9%A1%B5%E6%8A%93%E5%8F%96/3055542?fr=ge_ala
https://blog.csdn.net/qq_44273429/article/details/128776637
https://zhuanlan.zhihu.com/p/34206711?utm_source=com.tencent.tim