Robots协议
摘要:Robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个Robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。 免费下载软件
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。
简介
Robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个Robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。
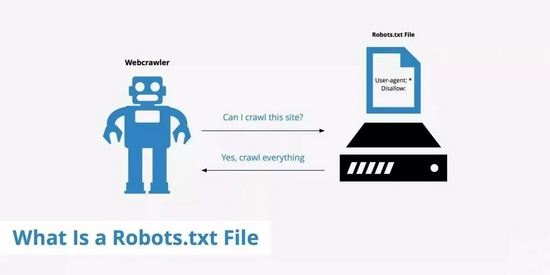
适用场景
Robots协议目的是帮助网站管理员控制搜索引擎蜘蛛的访问,以保护私有内容、减少服务器负载,或引导蜘蛛访问站点的特定部分。Robots协议规定了一些指令,如”User-agent”(指定蜘蛛)和”Disallow”(指定禁止访问的路径),用于指导搜索引擎蜘蛛如何爬取网站。
这种协议对于搜索引擎优化(SEO)和网站安全性都很重要,网站管理员可以使用robots.txt来指定哪些内容对搜索引擎公开,哪些不应该被索引。
优点:Robots协议允许网站管理员明确控制搜索引擎蜘蛛的访问,从而维护网站内容的隐私和安全。这有助于降低服务器负载,提高网站性能,同时可以为不同的搜索引擎定制不同的规则,以更精细地控制它们的抓取行为。此外,Robots协议可以防止搜索引擎重复索引相同内容的多个副本,从而提高搜索结果的质量。
缺陷:首先,它并不是网站的安全措施,因为不是所有搜索引擎都会遵循这些规则,而且有些恶意爬虫可能不会遵守协议。其次,尽管可以指定哪些页面不应被抓取,但这并不意味着页面内容是私有的。Robots协议只是搜索引擎的一个指南,而不是真正的安全措施。此外,Robots协议无法阻止用户直接访问被禁止索引的页面,因为它只是搜索引擎蜘蛛的指南。最后,需要正确配置Robots协议,否则可能导致搜索引擎无法索引网站的重要内容,需要谨慎配置和维护。
图例
1. Robots协议结构。
2. Robots协议写法示例。

相关名词
参考资料
https://baike.baidu.com/item/robots%E5%8D%8F%E8%AE%AE/2483797?fr=ge_ala