反爬虫机制(Anti-Scrapingtechniques)
反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。
2023-10-20 10:28:18
反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。
2023-10-20 10:28:18
网络爬虫,也称为Web爬虫或网络蜘蛛,是一种自动化的程序或脚本,被设计用来浏览互联网,以收集信息、数据或执行特定任务。这些任务可以包括搜索引擎索引、数据挖掘、价格比较、内容抓取、自动化测试等等。
2023-10-24 16:06:06
爬取频率是指网络爬虫或爬虫程序从目标网站上获取数据的时间间隔或频繁程度。
2023-10-24 14:24:57
数据抓取,也被称为网络爬虫、网页抓取、数据挖掘或网络数据采集,是指自动从互联网或计算机网络上提取信息、数据和内容的过程。这个过程通常通过编写计算机程序来实现,这些程序被称为爬虫或抓取器。
2023-10-23 10:55:14
后羿采集器一款真正免费的爬虫软件,针对采集数据所需要的基础功能,没有任何限制,不需要积分。
2018-08-20 15:53:10
Robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个Robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。
2023-10-24 15:03:49
网页抓取是指从互联网上获取信息或数据的过程,通常通过自动化的程序来执行。这些程序被称为网络爬虫或网络机器人,它们浏览网页、提取信息并将其存储或进一步处理。
2023-10-24 14:39:07
本教程为大家介绍如何在智能模式的任务编辑页面进行任务设置
2019-10-12 15:06:20
每股收益又称每股税后利润、每股盈余,是指税后利润与股本总数的比率,反映了企业经营成果中归属于每股普通股的盈利部分。
2024-12-23 14:45:13
关于“可以采集微信公众号 / 小程序 / 好友 / 朋友圈吗?”问题的回答。
2022-12-27 14:57:51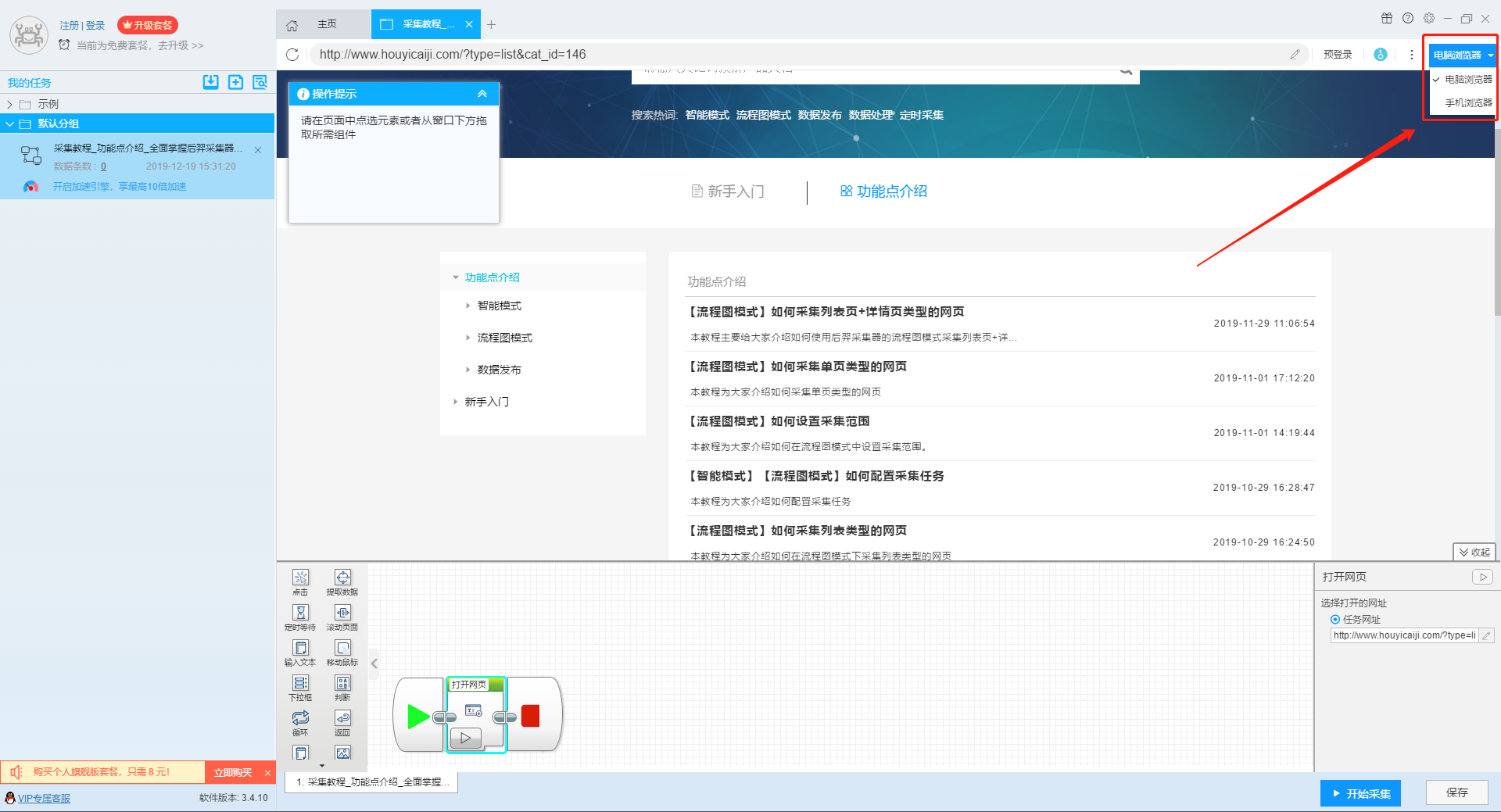
本教程为大家介绍在流程图模式中切换浏览器模式的作用
2018-12-17 15:43:33
LinkedIn是全球最大的职业社交平台,用户可以在此建立个人资料、发布专业信息、搜索工作机会并建立专业联系。同时,它还具备社交软件的即时通讯特性,让用户可以通过对话、群组、邮件等方式快速有效地建立联系。
2025-03-26 11:02:45